Qemu (short form for Quick Emulator) is an open source hypervisor that emulates a physical computer. From the perspective of the host system where Qemu is running, Qemu is a user program which has access to a number of local resources like partitions, files, network cards which are then passed to an emulated computer which sees them as if they were real devices.
A guest operating system running in the emulated computer accesses these devices, and runs as if it were running on real hardware. For instance, you can pass an ISO image as a parameter to Qemu, and the OS running in the emulated computer will see a real CD-ROM inserted into a CD drive.
Qemu can emulate a great variety of hardware from ARM to Sparc, but Proxmox VE is only concerned with 32 and 64 bits PC clone emulation, since it represents the overwhelming majority of server hardware. The emulation of PC clones is also one of the fastest due to the availability of processor extensions which greatly speed up Qemu when the emulated architecture is the same as the host architecture.
 |
You may sometimes encounter the term KVM (Kernel-based Virtual Machine). It means that Qemu is running with the support of the virtualization processor extensions, via the Linux KVM module. In the context of Proxmox VE Qemu and KVM can be used interchangeably, as Qemu in Proxmox VE will always try to load the KVM module. |
Qemu inside Proxmox VE runs as a root process, since this is required to access block and PCI devices.
Emulated devices and paravirtualized devices
The PC hardware emulated by Qemu includes a mainboard, network controllers, SCSI, IDE and SATA controllers, serial ports (the complete list can be seen in the kvm(1) man page) all of them emulated in software. All these devices are the exact software equivalent of existing hardware devices, and if the OS running in the guest has the proper drivers it will use the devices as if it were running on real hardware. This allows Qemu to runs unmodified operating systems.
This however has a performance cost, as running in software what was meant to run in hardware involves a lot of extra work for the host CPU. To mitigate this, Qemu can present to the guest operating system paravirtualized devices, where the guest OS recognizes it is running inside Qemu and cooperates with the hypervisor.
Qemu relies on the virtio virtualization standard, and is thus able to present paravirtualized virtio devices, which includes a paravirtualized generic disk controller, a paravirtualized network card, a paravirtualized serial port, a paravirtualized SCSI controller, etc …
It is highly recommended to use the virtio devices whenever you can, as they provide a big performance improvement. Using the virtio generic disk controller versus an emulated IDE controller will double the sequential write throughput, as measured with bonnie++(8). Using the virtio network interface can deliver up to three times the throughput of an emulated Intel E1000 network card, as measured with iperf(1). [1]
Virtual Machines Settings
Generally speaking Proxmox VE tries to choose sane defaults for virtual machines (VM). Make sure you understand the meaning of the settings you change, as it could incur a performance slowdown, or putting your data at risk.
General Settings
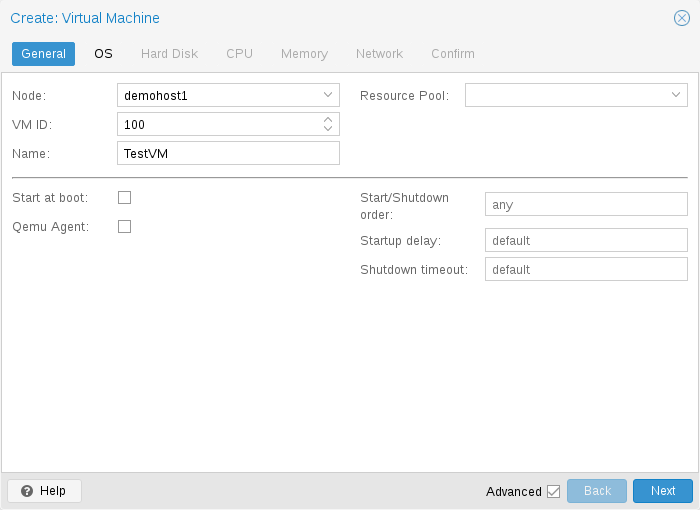
General settings of a VM include
-
the Node : the physical server on which the VM will run
-
the VM ID: a unique number in this Proxmox VE installation used to identify your VM
-
Name: a free form text string you can use to describe the VM
-
Resource Pool: a logical group of VMs
OS Settings
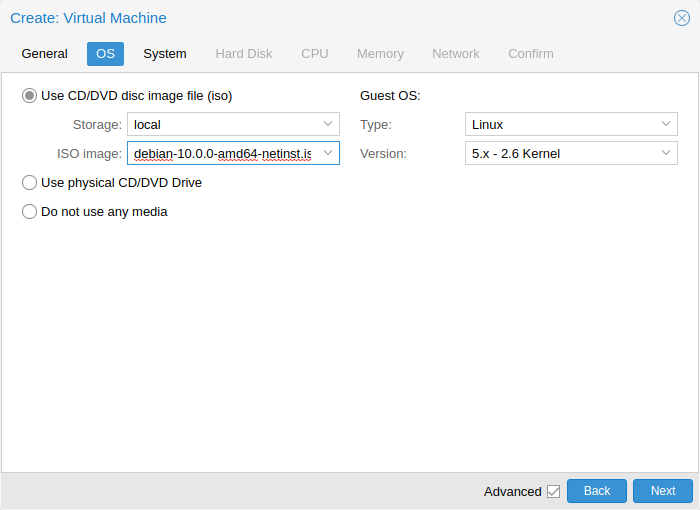
When creating a virtual machine (VM), setting the proper Operating System(OS) allows Proxmox VE to optimize some low level parameters. For instance Windows OS expect the BIOS clock to use the local time, while Unix based OS expect the BIOS clock to have the UTC time.
System Settings
On VM creation you can change some basic system components of the new VM. You can specify which display type you want to use.
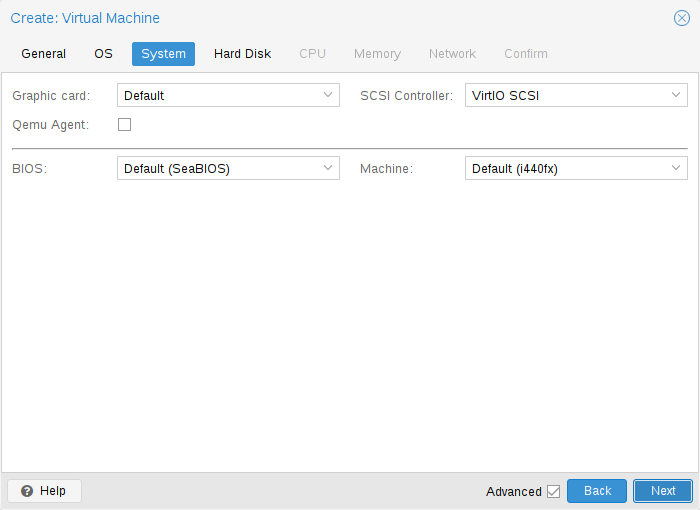
Additionally, the SCSI controller can be changed. If you plan to install the QEMU Guest Agent, or if your selected ISO image already ships and installs it automatically, you may want to tick the Qemu Agent box, which lets Proxmox VE know that it can use its features to show some more information, and complete some actions (for example, shutdown or snapshots) more intelligently.
Proxmox VE allows to boot VMs with different firmware and machine types, namely SeaBIOS and OVMF. In most cases you want to switch from the default SeaBIOS to OVMF only if you plan to use PCIe pass through. A VMs Machine Type defines the hardware layout of the VM’s virtual motherboard. You can choose between the default Intel 440FX or the Q35 chipset, which also provides a virtual PCIe bus, and thus may be desired if one wants to pass through PCIe hardware.
Hard Disk
Bus/Controller
Qemu can emulate a number of storage controllers:
-
the IDE controller, has a design which goes back to the 1984 PC/AT disk controller. Even if this controller has been superseded by recent designs, each and every OS you can think of has support for it, making it a great choice if you want to run an OS released before 2003. You can connect up to 4 devices on this controller.
-
the SATA (Serial ATA) controller, dating from 2003, has a more modern design, allowing higher throughput and a greater number of devices to be connected. You can connect up to 6 devices on this controller.
-
the SCSI controller, designed in 1985, is commonly found on server grade hardware, and can connect up to 14 storage devices. Proxmox VE emulates by default a LSI 53C895A controller.
A SCSI controller of type VirtIO SCSI is the recommended setting if you aim for performance and is automatically selected for newly created Linux VMs since Proxmox VE 4.3. Linux distributions have support for this controller since 2012, and FreeBSD since 2014. For Windows OSes, you need to provide an extra iso containing the drivers during the installation. If you aim at maximum performance, you can select a SCSI controller of type VirtIO SCSI single which will allow you to select the IO Thread option. When selecting VirtIO SCSI single Qemu will create a new controller for each disk, instead of adding all disks to the same controller.
-
The VirtIO Block controller, often just called VirtIO or virtio-blk, is an older type of paravirtualized controller. It has been superseded by the VirtIO SCSI Controller, in terms of features.
Image Format
On each controller you attach a number of emulated hard disks, which are backed by a file or a block device residing in the configured storage. The choice of a storage type will determine the format of the hard disk image. Storages which present block devices (LVM, ZFS, Ceph) will require the raw disk image format, whereas files based storages (Ext4, NFS, CIFS, GlusterFS) will let you to choose either the raw disk image format or the QEMU image format.
-
the QEMU image format is a copy on write format which allows snapshots, and thin provisioning of the disk image.
-
the raw disk image is a bit-to-bit image of a hard disk, similar to what you would get when executing the dd command on a block device in Linux. This format does not support thin provisioning or snapshots by itself, requiring cooperation from the storage layer for these tasks. It may, however, be up to 10% faster than the QEMU image format. [2]
-
the VMware image format only makes sense if you intend to import/export the disk image to other hypervisors.
Cache Mode
Setting the Cache mode of the hard drive will impact how the host system will notify the guest systems of block write completions. The No cache default means that the guest system will be notified that a write is complete when each block reaches the physical storage write queue, ignoring the host page cache. This provides a good balance between safety and speed.
If you want the Proxmox VE backup manager to skip a disk when doing a backup of a VM, you can set the No backup option on that disk.
If you want the Proxmox VE storage replication mechanism to skip a disk when starting a replication job, you can set the Skip replication option on that disk. As of Proxmox VE 5.0, replication requires the disk images to be on a storage of type zfspool, so adding a disk image to other storages when the VM has replication configured requires to skip replication for this disk image.
Trim/Discard
If your storage supports thin provisioning (see the storage chapter in the Proxmox VE guide), you can activate the Discard option on a drive. With Discard set and a TRIM-enabled guest OS [3], when the VM’s filesystem marks blocks as unused after deleting files, the controller will relay this information to the storage, which will then shrink the disk image accordingly. For the guest to be able to issue TRIM commands, you must enable the Discard option on the drive. Some guest operating systems may also require the SSD Emulation flag to be set. Note that Discard on VirtIO Block drives is only supported on guests using Linux Kernel 5.0 or higher.
If you would like a drive to be presented to the guest as a solid-state drive rather than a rotational hard disk, you can set the SSD emulation option on that drive. There is no requirement that the underlying storage actually be backed by SSDs; this feature can be used with physical media of any type. Note that SSD emulation is not supported on VirtIO Block drives.
IO Thread
The option IO Thread can only be used when using a disk with the VirtIO controller, or with the SCSI controller, when the emulated controller type is VirtIO SCSI single. With this enabled, Qemu creates one I/O thread per storage controller, rather than a single thread for all I/O. This can increase performance when multiple disks are used and each disk has its own storage controller.
CPU
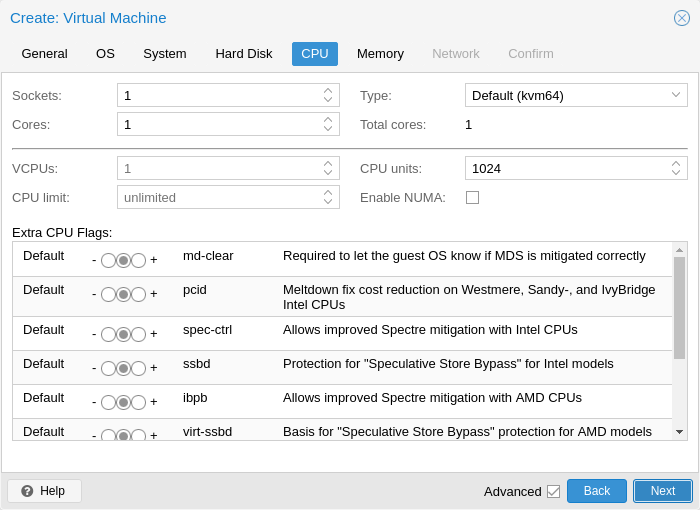
A CPU socket is a physical slot on a PC motherboard where you can plug a CPU. This CPU can then contain one or many cores, which are independent processing units. Whether you have a single CPU socket with 4 cores, or two CPU sockets with two cores is mostly irrelevant from a performance point of view. However some software licenses depend on the number of sockets a machine has, in that case it makes sense to set the number of sockets to what the license allows you.
Increasing the number of virtual CPUs (cores and sockets) will usually provide a performance improvement though that is heavily dependent on the use of the VM. Multi-threaded applications will of course benefit from a large number of virtual CPUs, as for each virtual cpu you add, Qemu will create a new thread of execution on the host system. If you’re not sure about the workload of your VM, it is usually a safe bet to set the number of Total cores to 2.
|
It is perfectly safe if the overall number of cores of all your VMs is greater than the number of cores on the server (e.g., 4 VMs with each 4 cores on a machine with only 8 cores). In that case the host system will balance the Qemu execution threads between your server cores, just like if you were running a standard multi-threaded application. However, Proxmox VE will prevent you from starting VMs with more virtual CPU cores than physically available, as this will only bring the performance down due to the cost of context switches. |
Resource Limits
In addition to the number of virtual cores, you can configure how much resources a VM can get in relation to the host CPU time and also in relation to other VMs. With the cpulimit (“Host CPU Time”) option you can limit how much CPU time the whole VM can use on the host. It is a floating point value representing CPU time in percent, so 1.0 is equal to 100%, 2.5 to 250% and so on. If a single process would fully use one single core it would have 100% CPU Time usage. If a VM with four cores utilizes all its cores fully it would theoretically use 400%. In reality the usage may be even a bit higher as Qemu can have additional threads for VM peripherals besides the vCPU core ones. This setting can be useful if a VM should have multiple vCPUs, as it runs a few processes in parallel, but the VM as a whole should not be able to run all vCPUs at 100% at the same time. Using a specific example: lets say we have a VM which would profit from having 8 vCPUs, but at no time all of those 8 cores should run at full load - as this would make the server so overloaded that other VMs and CTs would get to less CPU. So, we set the cpulimit limit to 4.0 (=400%). If all cores do the same heavy work they would all get 50% of a real host cores CPU time. But, if only 4 would do work they could still get almost 100% of a real core each.
|
VMs can, depending on their configuration, use additional threads e.g., for networking or IO operations but also live migration. Thus a VM can show up to use more CPU time than just its virtual CPUs could use. To ensure that a VM never uses more CPU time than virtual CPUs assigned set the cpulimit setting to the same value as the total core count. |
The second CPU resource limiting setting, cpuunits (nowadays often called CPU shares or CPU weight), controls how much CPU time a VM gets in regards to other VMs running. It is a relative weight which defaults to 1024, if you increase this for a VM it will be prioritized by the scheduler in comparison to other VMs with lower weight. E.g., if VM 100 has set the default 1024 and VM 200 was changed to 2048, the latter VM 200 would receive twice the CPU bandwidth than the first VM 100.
For more information see man systemd.resource-control, here CPUQuota corresponds to cpulimit and CPUShares corresponds to our cpuunits setting, visit its Notes section for references and implementation details.
CPU Type
Qemu can emulate a number different of CPU types from 486 to the latest Xeon processors. Each new processor generation adds new features, like hardware assisted 3d rendering, random number generation, memory protection, etc … Usually you should select for your VM a processor type which closely matches the CPU of the host system, as it means that the host CPU features (also called CPU flags ) will be available in your VMs. If you want an exact match, you can set the CPU type to host in which case the VM will have exactly the same CPU flags as your host system.
This has a downside though. If you want to do a live migration of VMs between different hosts, your VM might end up on a new system with a different CPU type. If the CPU flags passed to the guest are missing, the qemu process will stop. To remedy this Qemu has also its own CPU type kvm64, that Proxmox VE uses by defaults. kvm64 is a Pentium 4 look a like CPU type, which has a reduced CPU flags set, but is guaranteed to work everywhere.
In short, if you care about live migration and moving VMs between nodes, leave the kvm64 default. If you don’t care about live migration or have a homogeneous cluster where all nodes have the same CPU, set the CPU type to host, as in theory this will give your guests maximum performance.
Custom CPU Types
You can specify custom CPU types with a configurable set of features. These are maintained in the configuration file /etc/pve/virtual-guest/cpu-models.conf by an administrator. See man cpu-models.conf for format details.
Specified custom types can be selected by any user with the Sys.Audit privilege on /nodes. When configuring a custom CPU type for a VM via the CLI or API, the name needs to be prefixed with custom-.
Meltdown / Spectre related CPU flags
There are several CPU flags related to the Meltdown and Spectre vulnerabilities [4] which need to be set manually unless the selected CPU type of your VM already enables them by default.
There are two requirements that need to be fulfilled in order to use these CPU flags:
-
The host CPU(s) must support the feature and propagate it to the guest’s virtual CPU(s)
-
The guest operating system must be updated to a version which mitigates the attacks and is able to utilize the CPU feature
Otherwise you need to set the desired CPU flag of the virtual CPU, either by editing the CPU options in the WebUI, or by setting the flags property of the cpu option in the VM configuration file.
For Spectre v1,v2,v4 fixes, your CPU or system vendor also needs to provide a so-called “microcode update” [5] for your CPU.
To check if the Proxmox VE host is vulnerable, execute the following command as root:
for f in /sys/devices/system/cpu/vulnerabilities/*; do echo "${f##*/} -" $(cat "$f"); done
A community script is also available to detect is the host is still vulnerable. [6]
Intel processors
-
pcid
This reduces the performance impact of the Meltdown (CVE-2017-5754) mitigation called Kernel Page-Table Isolation (KPTI), which effectively hides the Kernel memory from the user space. Without PCID, KPTI is quite an expensive mechanism [7].
To check if the Proxmox VE host supports PCID, execute the following command as root:
# grep ' pcid ' /proc/cpuinfo
If this does not return empty your host’s CPU has support for pcid.
-
spec-ctrl
Required to enable the Spectre v1 (CVE-2017-5753) and Spectre v2 (CVE-2017-5715) fix, in cases where retpolines are not sufficient. Included by default in Intel CPU models with -IBRS suffix. Must be explicitly turned on for Intel CPU models without -IBRS suffix. Requires an updated host CPU microcode (intel-microcode >= 20180425).
-
ssbd
Required to enable the Spectre V4 (CVE-2018-3639) fix. Not included by default in any Intel CPU model. Must be explicitly turned on for all Intel CPU models. Requires an updated host CPU microcode(intel-microcode >= 20180703).
AMD processors
-
ibpb
Required to enable the Spectre v1 (CVE-2017-5753) and Spectre v2 (CVE-2017-5715) fix, in cases where retpolines are not sufficient. Included by default in AMD CPU models with -IBPB suffix. Must be explicitly turned on for AMD CPU models without -IBPB suffix. Requires the host CPU microcode to support this feature before it can be used for guest CPUs.
-
virt-ssbd
Required to enable the Spectre v4 (CVE-2018-3639) fix. Not included by default in any AMD CPU model. Must be explicitly turned on for all AMD CPU models. This should be provided to guests, even if amd-ssbd is also provided, for maximum guest compatibility. Note that this must be explicitly enabled when when using the "host" cpu model, because this is a virtual feature which does not exist in the physical CPUs.
-
amd-ssbd
Required to enable the Spectre v4 (CVE-2018-3639) fix. Not included by default in any AMD CPU model. Must be explicitly turned on for all AMD CPU models. This provides higher performance than virt-ssbd, therefore a host supporting this should always expose this to guests if possible. virt-ssbd should none the less also be exposed for maximum guest compatibility as some kernels only know about virt-ssbd.
-
amd-no-ssb
Recommended to indicate the host is not vulnerable to Spectre V4 (CVE-2018-3639). Not included by default in any AMD CPU model. Future hardware generations of CPU will not be vulnerable to CVE-2018-3639, and thus the guest should be told not to enable its mitigations, by exposing amd-no-ssb. This is mutually exclusive with virt-ssbd and amd-ssbd.
NUMA
You can also optionally emulate a NUMA [8] architecture in your VMs. The basics of the NUMA architecture mean that instead of having a global memory pool available to all your cores, the memory is spread into local banks close to each socket. This can bring speed improvements as the memory bus is not a bottleneck anymore. If your system has a NUMA architecture [9] we recommend to activate the option, as this will allow proper distribution of the VM resources on the host system. This option is also required to hot-plug cores or RAM in a VM.
If the NUMA option is used, it is recommended to set the number of sockets to the number of nodes of the host system.
vCPU hot-plug
Modern operating systems introduced the capability to hot-plug and, to a certain extent, hot-unplug CPUs in a running system. Virtualization allows us to avoid a lot of the (physical) problems real hardware can cause in such scenarios. Still, this is a rather new and complicated feature, so its use should be restricted to cases where its absolutely needed. Most of the functionality can be replicated with other, well tested and less complicated, features, see Resource Limits.
In Proxmox VE the maximal number of plugged CPUs is always cores * sockets. To start a VM with less than this total core count of CPUs you may use the vpus setting, it denotes how many vCPUs should be plugged in at VM start.
Currently only this feature is only supported on Linux, a kernel newer than 3.10 is needed, a kernel newer than 4.7 is recommended.
You can use a udev rule as follow to automatically set new CPUs as online in the guest:
SUBSYSTEM=="cpu", ACTION=="add", TEST=="online", ATTR{online}=="0", ATTR{online}="1"
Save this under /etc/udev/rules.d/ as a file ending in .rules.
Note: CPU hot-remove is machine dependent and requires guest cooperation. The deletion command does not guarantee CPU removal to actually happen, typically it’s a request forwarded to guest using target dependent mechanism, e.g., ACPI on x86/amd64.
Memory
For each VM you have the option to set a fixed size memory or asking Proxmox VE to dynamically allocate memory based on the current RAM usage of the host.
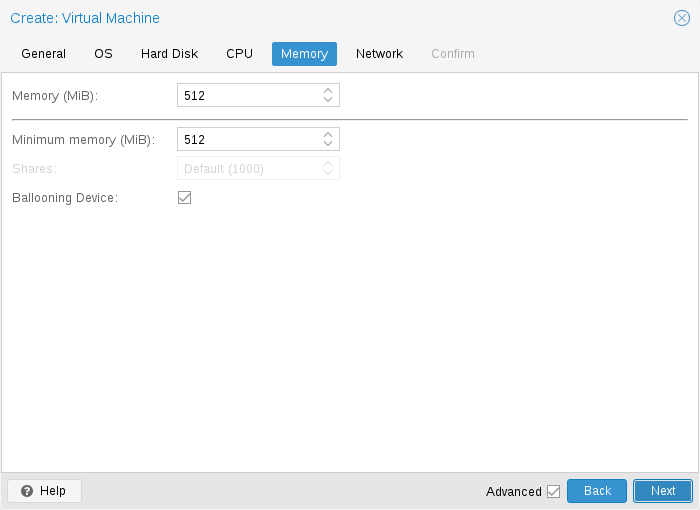
Fixed Memory Allocation
When setting memory and minimum memory to the same amount Proxmox VE will simply allocate what you specify to your VM.
Even when using a fixed memory size, the ballooning device gets added to the VM, because it delivers useful information such as how much memory the guest really uses. In general, you should leave ballooning enabled, but if you want to disable it (e.g. for debugging purposes), simply uncheck Ballooning Device or set
balloon: 0
in the configuration.
Automatic Memory Allocation
When setting the minimum memory lower than memory, Proxmox VE will make sure that the minimum amount you specified is always available to the VM, and if RAM usage on the host is below 80%, will dynamically add memory to the guest up to the maximum memory specified.
When the host is running low on RAM, the VM will then release some memory back to the host, swapping running processes if needed and starting the oom killer in last resort. The passing around of memory between host and guest is done via a special balloon kernel driver running inside the guest, which will grab or release memory pages from the host. [10]
When multiple VMs use the autoallocate facility, it is possible to set a Shares coefficient which indicates the relative amount of the free host memory that each VM should take. Suppose for instance you have four VMs, three of them running an HTTP server and the last one is a database server. To cache more database blocks in the database server RAM, you would like to prioritize the database VM when spare RAM is available. For this you assign a Shares property of 3000 to the database VM, leaving the other VMs to the Shares default setting of 1000. The host server has 32GB of RAM, and is currently using 16GB, leaving 32 * 80/100 - 16 = 9GB RAM to be allocated to the VMs. The database VM will get 9 * 3000 / (3000 + 1000 + 1000 + 1000) = 4.5 GB extra RAM and each HTTP server will get 1.5 GB.
All Linux distributions released after 2010 have the balloon kernel driver included. For Windows OSes, the balloon driver needs to be added manually and can incur a slowdown of the guest, so we don’t recommend using it on critical systems.
When allocating RAM to your VMs, a good rule of thumb is always to leave 1GB of RAM available to the host.
Network Device
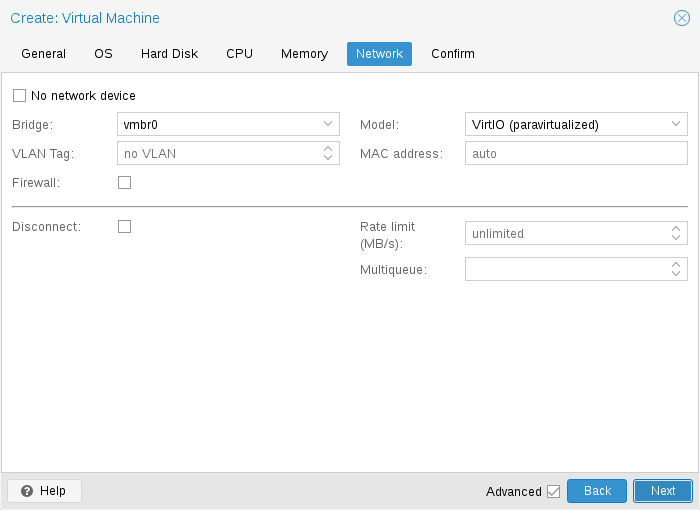
Each VM can have many Network interface controllers (NIC), of four different types:
-
Intel E1000 is the default, and emulates an Intel Gigabit network card.
-
the VirtIO paravirtualized NIC should be used if you aim for maximum performance. Like all VirtIO devices, the guest OS should have the proper driver installed.
-
the Realtek 8139 emulates an older 100 MB/s network card, and should only be used when emulating older operating systems ( released before 2002 )
-
the vmxnet3 is another paravirtualized device, which should only be used when importing a VM from another hypervisor.
Proxmox VE will generate for each NIC a random MAC address, so that your VM is addressable on Ethernet networks.
The NIC you added to the VM can follow one of two different models:
-
in the default Bridged mode each virtual NIC is backed on the host by a tap device, ( a software loopback device simulating an Ethernet NIC ). This tap device is added to a bridge, by default vmbr0 in Proxmox VE. In this mode, VMs have direct access to the Ethernet LAN on which the host is located.
-
in the alternative NAT mode, each virtual NIC will only communicate with the Qemu user networking stack, where a built-in router and DHCP server can provide network access. This built-in DHCP will serve addresses in the private 10.0.2.0/24 range. The NAT mode is much slower than the bridged mode, and should only be used for testing. This mode is only available via CLI or the API, but not via the WebUI.
You can also skip adding a network device when creating a VM by selecting No network device.
Multiqueue
If you are using the VirtIO driver, you can optionally activate the Multiqueue option. This option allows the guest OS to process networking packets using multiple virtual CPUs, providing an increase in the total number of packets transferred.
When using the VirtIO driver with Proxmox VE, each NIC network queue is passed to the host kernel, where the queue will be processed by a kernel thread spawned by the vhost driver. With this option activated, it is possible to pass multiple network queues to the host kernel for each NIC.
When using Multiqueue, it is recommended to set it to a value equal to the number of Total Cores of your guest. You also need to set in the VM the number of multi-purpose channels on each VirtIO NIC with the ethtool command:
ethtool -L ens1 combined X
where X is the number of the number of vcpus of the VM.
You should note that setting the Multiqueue parameter to a value greater than one will increase the CPU load on the host and guest systems as the traffic increases. We recommend to set this option only when the VM has to process a great number of incoming connections, such as when the VM is running as a router, reverse proxy or a busy HTTP server doing long polling.
Display
QEMU can virtualize a few types of VGA hardware. Some examples are:
-
std, the default, emulates a card with Bochs VBE extensions.
-
cirrus, this was once the default, it emulates a very old hardware module with all its problems. This display type should only be used if really necessary [11], e.g., if using Windows XP or earlier
-
vmware, is a VMWare SVGA-II compatible adapter.
-
qxl, is the QXL paravirtualized graphics card. Selecting this also enables SPICE (a remote viewer protocol) for the VM.
You can edit the amount of memory given to the virtual GPU, by setting the memory option. This can enable higher resolutions inside the VM, especially with SPICE/QXL.
As the memory is reserved by display device, selecting Multi-Monitor mode for SPICE (e.g., qxl2 for dual monitors) has some implications:
-
Windows needs a device for each monitor, so if your ostype is some version of Windows, Proxmox VE gives the VM an extra device per monitor. Each device gets the specified amount of memory.
-
Linux VMs, can always enable more virtual monitors, but selecting a Multi-Monitor mode multiplies the memory given to the device with the number of monitors.
Selecting serialX as display type disables the VGA output, and redirects the Web Console to the selected serial port. A configured display memory setting will be ignored in that case.
USB Passthrough
There are two different types of USB passthrough devices:
-
Host USB passthrough
-
SPICE USB passthrough
Host USB passthrough works by giving a VM a USB device of the host. This can either be done via the vendor- and product-id, or via the host bus and port.
The vendor/product-id looks like this: 0123:abcd, where 0123 is the id of the vendor, and abcd is the id of the product, meaning two pieces of the same usb device have the same id.
The bus/port looks like this: 1-2.3.4, where 1 is the bus and 2.3.4 is the port path. This represents the physical ports of your host (depending of the internal order of the usb controllers).
If a device is present in a VM configuration when the VM starts up, but the device is not present in the host, the VM can boot without problems. As soon as the device/port is available in the host, it gets passed through.
 |
Using this kind of USB passthrough means that you cannot move a VM online to another host, since the hardware is only available on the host the VM is currently residing. |
The second type of passthrough is SPICE USB passthrough. This is useful if you use a SPICE client which supports it. If you add a SPICE USB port to your VM, you can passthrough a USB device from where your SPICE client is, directly to the VM (for example an input device or hardware dongle).
BIOS and UEFI
In order to properly emulate a computer, QEMU needs to use a firmware. Which, on common PCs often known as BIOS or (U)EFI, is executed as one of the first steps when booting a VM. It is responsible for doing basic hardware initialization and for providing an interface to the firmware and hardware for the operating system. By default QEMU uses SeaBIOS for this, which is an open-source, x86 BIOS implementation. SeaBIOS is a good choice for most standard setups.
There are, however, some scenarios in which a BIOS is not a good firmware to boot from, e.g. if you want to do VGA passthrough. [12] In such cases, you should rather use OVMF, which is an open-source UEFI implementation. [13]
If you want to use OVMF, there are several things to consider:
In order to save things like the boot order, there needs to be an EFI Disk. This disk will be included in backups and snapshots, and there can only be one.
You can create such a disk with the following command:
qm set <vmid> -efidisk0 <storage>:1,format=<format>
Where <storage> is the storage where you want to have the disk, and <format> is a format which the storage supports. Alternatively, you can create such a disk through the web interface with Add → EFI Disk in the hardware section of a VM.
When using OVMF with a virtual display (without VGA passthrough), you need to set the client resolution in the OVMF menu(which you can reach with a press of the ESC button during boot), or you have to choose SPICE as the display type.
Inter-VM shared memory
You can add an Inter-VM shared memory device (ivshmem), which allows one to share memory between the host and a guest, or also between multiple guests.
To add such a device, you can use qm:
qm set <vmid> -ivshmem size=32,name=foo
Where the size is in MiB. The file will be located under /dev/shm/pve-shm-$name (the default name is the vmid).
|
Currently the device will get deleted as soon as any VM using it got shutdown or stopped. Open connections will still persist, but new connections to the exact same device cannot be made anymore. |
A use case for such a device is the Looking Glass [14] project, which enables high performance, low-latency display mirroring between host and guest.
Audio Device
To add an audio device run the following command:
qm set <vmid> -audio0 device=<device>
Supported audio devices are:
-
ich9-intel-hda: Intel HD Audio Controller, emulates ICH9
-
intel-hda: Intel HD Audio Controller, emulates ICH6
-
AC97: Audio Codec '97, useful for older operating systems like Windows XP
There are two backends available:
-
spice
-
none
The spice backend can be used in combination with SPICE while the none backend can be useful if an audio device is needed in the VM for some software to work. To use the physical audio device of the host use device passthrough (see PCI Passthrough and USB Passthrough). Remote protocols like Microsoft’s RDP have options to play sound.
VirtIO RNG
A RNG (Random Number Generator) is a device providing entropy (randomness) to a system. A virtual hardware-RNG can be used to provide such entropy from the host system to a guest VM. This helps to avoid entropy starvation problems in the guest (a situation where not enough entropy is available and the system may slow down or run into problems), especially during the guests boot process.
To add a VirtIO-based emulated RNG, run the following command:
qm set <vmid> -rng0 source=<source>[,max_bytes=X,period=Y]
source specifies where entropy is read from on the host and has to be one of the following:
-
/dev/urandom: Non-blocking kernel entropy pool (preferred)
-
/dev/random: Blocking kernel pool (not recommended, can lead to entropy starvation on the host system)
-
/dev/hwrng: To pass through a hardware RNG attached to the host (if multiple are available, the one selected in /sys/devices/virtual/misc/hw_random/rng_current will be used)
A limit can be specified via the max_bytes and period parameters, they are read as max_bytes per period in milliseconds. However, it does not represent a linear relationship: 1024B/1000ms would mean that up to 1 KiB of data becomes available on a 1 second timer, not that 1 KiB is streamed to the guest over the course of one second. Reducing the period can thus be used to inject entropy into the guest at a faster rate.
By default, the limit is set to 1024 bytes per 1000 ms (1 KiB/s). It is recommended to always use a limiter to avoid guests using too many host resources. If desired, a value of 0 for max_bytes can be used to disable all limits.
Device Boot Order
QEMU can tell the guest which devices it should boot from, and in which order. This can be specified in the config via the boot property, e.g.:
boot: order=scsi0;net0;hostpci0
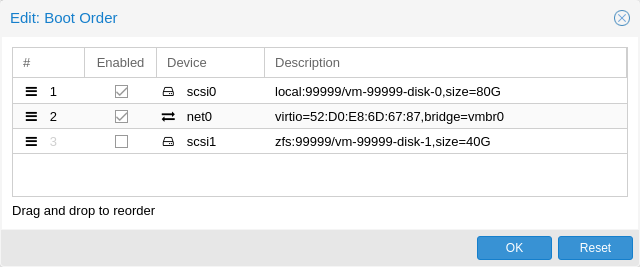
This way, the guest would first attempt to boot from the disk scsi0, if that fails, it would go on to attempt network boot from net0, and in case that fails too, finally attempt to boot from a passed through PCIe device (seen as disk in case of NVMe, otherwise tries to launch into an option ROM).
On the GUI you can use a drag-and-drop editor to specify the boot order, and use the checkbox to enable or disable certain devices for booting altogether.
|
If your guest uses multiple disks to boot the OS or load the bootloader, all of them must be marked as bootable (that is, they must have the checkbox enabled or appear in the list in the config) for the guest to be able to boot. This is because recent SeaBIOS and OVMF versions only initialize disks if they are marked bootable. |
In any case, even devices not appearing in the list or having the checkmark disabled will still be available to the guest, once it’s operating system has booted and initialized them. The bootable flag only affects the guest BIOS and bootloader.
Automatic Start and Shutdown of Virtual Machines
After creating your VMs, you probably want them to start automatically when the host system boots. For this you need to select the option Start at boot from the Options Tab of your VM in the web interface, or set it with the following command:
qm set <vmid> -onboot 1
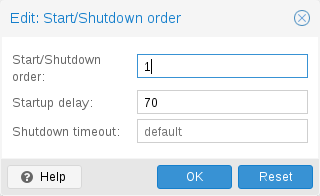
Start and Shutdown Order
In some case you want to be able to fine tune the boot order of your VMs, for instance if one of your VM is providing firewalling or DHCP to other guest systems. For this you can use the following parameters:
-
Start/Shutdown order: Defines the start order priority. E.g. set it to 1 if you want the VM to be the first to be started. (We use the reverse startup order for shutdown, so a machine with a start order of 1 would be the last to be shut down). If multiple VMs have the same order defined on a host, they will additionally be ordered by VMID in ascending order.
-
Startup delay: Defines the interval between this VM start and subsequent VMs starts . E.g. set it to 240 if you want to wait 240 seconds before starting other VMs.
-
Shutdown timeout: Defines the duration in seconds Proxmox VE should wait for the VM to be offline after issuing a shutdown command. By default this value is set to 180, which means that Proxmox VE will issue a shutdown request and wait 180 seconds for the machine to be offline. If the machine is still online after the timeout it will be stopped forcefully.
|
VMs managed by the HA stack do not follow the start on boot and boot order options currently. Those VMs will be skipped by the startup and shutdown algorithm as the HA manager itself ensures that VMs get started and stopped. |
Please note that machines without a Start/Shutdown order parameter will always start after those where the parameter is set. Further, this parameter can only be enforced between virtual machines running on the same host, not cluster-wide.
Qemu Guest Agent
The Qemu Guest Agent is a service which runs inside the VM, providing a communication channel between the host and the guest. It is used to exchange information and allows the host to issue commands to the guest.
For example, the IP addresses in the VM summary panel are fetched via the guest agent.
Or when starting a backup, the guest is told via the guest agent to sync outstanding writes via the fs-freeze and fs-thaw commands.
For the guest agent to work properly the following steps must be taken:
-
install the agent in the guest and make sure it is running
-
enable the communication via the agent in Proxmox VE
Install Guest Agent
For most Linux distributions, the guest agent is available. The package is usually named qemu-guest-agent.
For Windows, it can be installed from the Fedora VirtIO driver ISO.
Enable Guest Agent Communication
Communication from Proxmox VE with the guest agent can be enabled in the VM’s Options panel. A fresh start of the VM is necessary for the changes to take effect.
It is possible to enable the Run guest-trim option. With this enabled, Proxmox VE will issue a trim command to the guest after the following operations that have the potential to write out zeros to the storage:
-
moving a disk to another storage
-
live migrating a VM to another node with local storage
On a thin provisioned storage, this can help to free up unused space.
Troubleshooting
VM does not shut down
Make sure the guest agent is installed and running.
Once the guest agent is enabled, Proxmox VE will send power commands like shutdown via the guest agent. If the guest agent is not running, commands cannot get executed properly and the shutdown command will run into a timeout.
SPICE Enhancements
SPICE Enhancements are optional features that can improve the remote viewer experience.
To enable them via the GUI go to the Options panel of the virtual machine. Run the following command to enable them via the CLI:
qm set <vmid> -spice_enhancements foldersharing=1,videostreaming=all
|
To use these features the Display of the virtual machine must be set to SPICE (qxl). |
Folder Sharing
Share a local folder with the guest. The spice-webdavd daemon needs to be installed in the guest. It makes the shared folder available through a local WebDAV server located at http://localhost:9843.
For Windows guests the installer for the Spice WebDAV daemon can be downloaded from the official SPICE website.
Most Linux distributions have a package called spice-webdavd that can be installed.
To share a folder in Virt-Viewer (Remote Viewer) go to File → Preferences. Select the folder to share and then enable the checkbox.
|
Folder sharing currently only works in the Linux version of Virt-Viewer. |
 |
Experimental! Currently this feature does not work reliably. |
Video Streaming
Fast refreshing areas are encoded into a video stream. Two options exist:
-
all: Any fast refreshing area will be encoded into a video stream.
-
filter: Additional filters are used t
- 7 Users Found This Useful
